
Creating Neural Networks in Tensorflow
This is a write-up and code tutorial that I wrote for an AI workshop given at UCLA, at which I gave a talk on neural networks and implementing them in Tensorflow. It’s part of a series on machine learning with Tensorflow, and the tutorials for the rest of them are available here.
Recap: The Learning Problem
We have a large dataset of \((x, y)\) pairs where \(x\) denotes a vector of features and \(y\) denotes the label for that feature vector. We want to learn a function \(h(x)\) that maps features to labels, with good generalization accuracy. We do this by minimizing a loss function computed on our dataset: \(\sum_{i=1}^{N} L(y_i, h(x_i))\). There are many loss functions we can choose. We have gone over the cross-entropy loss and variants of the squared error loss functions in previous workshops, and we will once again consider those today.
Review: A Single “Neuron”, aka the Perceptron
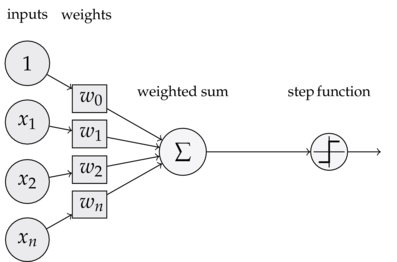
A single perceptron first calculates a weighted sum of our inputs. This means that we multiply each of our features \((x_1, x_2, ... x_n) \in x\) with an associated weight \((w_1, w_2, ... w_n)\) . We then take the sign of this linear combination, which and the sign tells us whether to classify this instance as a positive or negative example.
\[h(x) = sign(w^Tx + b)\]We then moved on to logistic regression, where we changed our sign function to instead be a sigmoid (\(\sigma\)) function. As a reminder, here’s the sigmoid function:

Therefore, the function we compute for logistic regression is \(h(x) = \sigma (w^Tx + b)\).
The sigmoid function is commonly referred to as an “activation” function. When we say that a “neuron computes an activation function”, it means that a standard linear combination is calculated (\(w^Tx + b\)) and then we apply a non linear function to it, such as the sigmoid function.
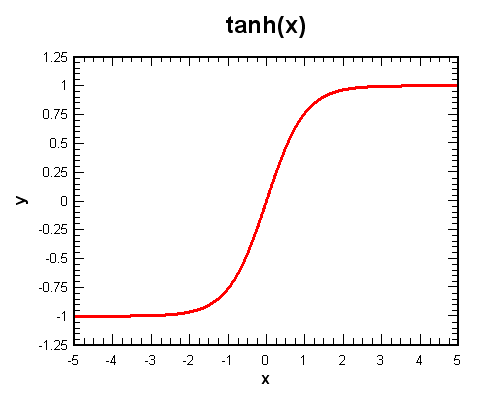
Here are a few other common activation functions:

Review: From binary to multi-class classification
The most important change in moving from a binary (negative/positive) classification model to one that can classify training instances into many different classes (say, 10, for MNIST) is that our vector of weights \(w\) changes into a matrix \(W\).
Each row of weights we learn represents the parameters for a certain class:

We also want to take our output and normalize the results so that they all sum to one, so that we can interpret them as probabilities. This is commonly done using the softmax function, which takes in a vector and returns another vector who’s elements sum to 1, and each element is proportional in scale to what it was in the original vector. In binary classification we used the sigmoid function to compute probabilities. Now since we have a vector, we use the softmax function.
Here is our current model of learning, then:
\(h(x) = softmax(Wx + b)\).
Building up the neural network
Now that we’ve figured out how to linearly model multi-class classification, we can create a basic neural network. Consider what happens when we combine the idea of artificial neurons with our softmax classifier. Instead of computing a linear function $Wx + b$ and immediately passing the output to a softmax function, we have an intermediate step: pass the output of our linear combination to a vector of artificial neurons, which each compute a nonlinear function.
The output of this “layer” of neurons can be multiplied with a matrix of weights again, and we can apply our softmax function to this result to produce our predictions.
Original function: \(h(x) = softmax(Wx + b)\)
Neural Network function: \(h(x) = softmax(W_2(nonlin(W_1x + b_1)) + b_2)\)
The key differences are that we have more biases and weights, as well as a larger composition of functions. This function is harder to optimize, and introduces a few interesting ideas about learning the weights with an algorithm known as backpropagation.
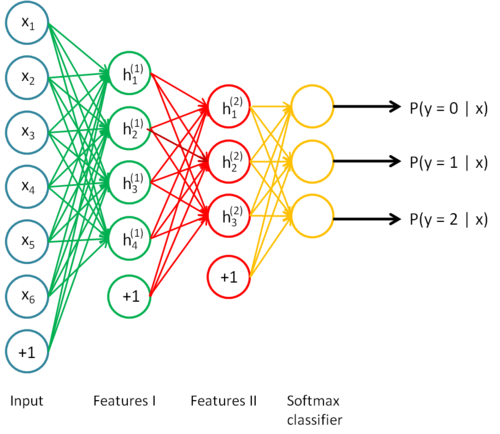
This “intermediate step” is actually known as a hidden layer, and we have complete control over it, meaning that among other things, we can vary the number of parameters or connections between weights and neurons to obtain an optimal network. It’s also important to notice that we can stack an arbitrary amount of these hidden layers between the input and output of our network, and we can tune these layers individually. This lets us make our network as deep as we want it. For example, here’s what a neural network with two hidden layers would look like:
We’re now ready to start implementing a basic neural network in Tensorflow. First, let’s start off with the standard import statements, and visualize a few examples from our training dataset.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # reads in the MNIST dataset
# a function that shows examples from the dataset. If num is specified (between 0 and 9), then only pictures with those labels will beused
def show_pics(mnist, num = None):
to_show = list(range(10)) if not num else [num]*10 # figure out which numbers we should show
for i in range(100):
batch = mnist.train.next_batch(1) # gets some examples
pic, label = batch[0], batch[1]
if np.argmax(label) in to_show:
# use matplotlib to plot it
pic = pic.reshape((28,28))
plt.title("Label: {}".format(np.argmax(label)))
plt.imshow(pic, cmap = 'binary')
plt.show()
to_show.remove(np.argmax(label))
#show_pics(mnist)
show_pics(mnist, 2)
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz


As usual, we would like to define several variables to represent our weight matrices and our biases. We will also need to create placeholders to hold our actual data. Anytime we want to create variables or placeholders, we must have a sense of the shape of our data so that Tensorflow has no issues in carrying out the numerical computations.
In addition, neural networks rely on various hyperparameters, some of which will be defined below. Two important ones are the ** learning rate ** and the number of neurons in our hidden layer. Depending on these settings, the accuracy of the network may greatly change.
# some functions for quick variable creation
def weight_variable(shape):
return tf.Variable(tf.truncated_normal(shape, stddev = 0.1))
def bias_variable(shape):
return tf.Variable(tf.constant(0.1, shape = shape))
# hyperparameters we will use
learning_rate = 0.1
hidden_layer_neurons = 50
num_iterations = 5000
# placeholder variables
x = tf.placeholder(tf.float32, shape = [None, 784]) # none = the size of that dimension doesn't matter. why is that okay here?
y_ = tf.placeholder(tf.float32, shape = [None, 10])
We will now actually create all of the variables we need, and define our neural network as a series of function computations.
In our first layer, we take our inputs that have dimension \(n * 784\), and multiply them with weights that have dimension \(784 * k\), where \(k\) is the number of neurons in the hidden layer. We then add the biases to this result, which also have a dimension of \(k\).
Finally, we apply a nonlinearity to our result. There are, as discussed, several choices, three of which are tanh, sigmoid, and rectifier. We have chosen to use the rectifier (also known as relu, standing for Rectified Linear Unit), since it has been shown in both research and practice that they tend to outperform and learn faster than other activation functions.
Therefore, the “activations” of our hidden layer are given by \(h_1 = relu(Wx + b)\).
We follow a similar procedure for our output layer. Our activations have a shape \(n * k\), where \(n\) is the number of training examples we input into our network and $k$ is the number of neurons in our hidden layer.
We want our final outputs to have dimension \(n * 10\) (in the case of MNIST) since we have 10 classes. Therefore, it makes sense for our second matrix of weights to have dimension \(k * 10\) and the bias to have dimension \(10\).
After taking the linear combination \(W_2(h_1) + b\), we would then apply the softmax function. However, applying the softmax function and then writing out the cross-entropy loss ourself could result in numerical unstability, so we will instead use a library call that computes both the softmax outputs and the cross entropy loss.
# create our weights and biases for our first hidden layer
W_1, b_1 = weight_variable([784, hidden_layer_neurons]), bias_variable([hidden_layer_neurons])
# compute activations of the hidden layer
h_1 = tf.nn.relu(tf.matmul(x, W_1) + b_1)
W_2_hidden = weight_variable([hidden_layer_neurons, 30])
b_2_hidden = bias_variable([30])
h_2 = tf.nn.relu(tf.matmul(h_1, W_2_hidden) + b_2_hidden)
# create our weights and biases for our output layer
W_2, b_2 = weight_variable([30, 10]), bias_variable([10])
# compute the of the output layer
y = tf.matmul(h_2,W_2) + b_2
The cross entropy loss function is a commonly used loss function. For a single prediction/label pair, it is given by \(C(h(x), y) = -\sum_i y_i log(h(x_i))\).*
Here, \(y\) is a specific one-hot encoded label vector, meaning that it is a column vector that has a 1 at the index corresponding to its label, and is zero everywhere else. \(h(x)\) is the output of our prediction function whose elements sum to 1. As an example, we may have:
\[y = \begin{bmatrix} 1 \\ 0 \\ 0 \end{bmatrix}, h(x_i) = \begin{bmatrix} 0.2 \\ 0.7 \\ 0.1 \end{bmatrix} \longrightarrow{} C(y, h(x)) = -\sum_{i=1}^{N}y_ilog(h(x_i)) = -log(0.2) = 0.61\]The contribution to the entire training data’s loss by this pair was 0.61. To contrast, we can swap the first two probabilities in our softmax vector. We then end up with a lower loss:
\[y = \begin{bmatrix} 1 \\ 0 \\ 0 \end{bmatrix}, h(x) = \begin{bmatrix} 0.7 \\ 0.2 \\ 0.1 \end{bmatrix} \longrightarrow{} C(y, h(x)) = -\sum_{i=1}^{N}y_ilog(h(x_i)) = -log(0.7) = 0.15\]So our cross-entropy loss makes intuitive sense: it is lower when our softmax vector has a high probability at the index of the true label, and it is higher when our probabilities indicate a wrong or uncertain choice.
Sanity check: why do we need the negative sign outside the sum?
# define our loss function as the cross entropy loss
cross_entropy_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels = y_, logits = y))
# create an optimizer to minimize our cross entropy loss
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy_loss)
# functions that allow us to gauge accuracy of our model
correct_predictions = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) # creates a vector where each element is T or F, denoting whether our prediction was right
accuracy = tf.reduce_mean(tf.cast(correct_predictions, tf.float32)) # maps the boolean values to 1.0 or 0.0 and calculates the accuracy
# we will need to run this in our session to initialize our weights and biases.
init = tf.global_variables_initializer()
With all of our variables created and computation graph defined, we can now launch the graph in a session and begin training. It is important to remember that since we declared the \(x\) and \(y\) variables as placeholders, we will need to feed in data to run our optimizer that minimizes the cross entropy loss.
The data we will feed in (by passing into our function a dictionary feed_dict) will come from the MNIST dataset. To randomly sample 100 training examples, we can use a wrapper provided by Tensorflow: mnnist.train.next_batch(100).
When we run the optimizer with the call optimizer.run(..) Tensorflow calculates a forward pass for us (essentially propagating our data through the graph we have described), and then uses the loss function we created to evaluate the loss, and then computes partial derivatives with respect to each set of weights and updates the weights according to the partial derivatives. This is called the backpropagation algorithm, and it involves significant application of the chain rule. CS 231N provides an excellent explanation of backpropagation.
# launch a session to run our graph defined above.
with tf.Session() as sess:
sess.run(init) # initializes our variables
for i in range(num_iterations):
# get a sample of the dataset and run the optimizer, which calculates a forward pass and then runs the backpropagation algorithm to improve the weights
batch = mnist.train.next_batch(100)
optimizer.run(feed_dict = {x: batch[0], y_: batch[1]})
# every 100 iterations, print out the accuracy
if i % 100 == 0:
# accuracy and loss are both functions that take (x, y) pairs as input, and run a forward pass through the network to obtain a prediction, and then compares the prediction with the actual y.
acc = accuracy.eval(feed_dict = {x: batch[0], y_: batch[1]})
loss = cross_entropy_loss.eval(feed_dict = {x: batch[0], y_: batch[1]})
print("Epoch: {}, accuracy: {}, loss: {}".format(i, acc, loss))
# evaluate our testing accuracy
acc = accuracy.eval(feed_dict = {x: mnist.test.images, y_: mnist.test.labels})
print("testing accuracy: {}".format(acc))
Epoch: 0, accuracy: 0.07999999821186066, loss: 2.2931833267211914
Epoch: 100, accuracy: 0.8399999737739563, loss: 0.6990350484848022
Epoch: 200, accuracy: 0.8700000047683716, loss: 0.35569435358047485
Epoch: 300, accuracy: 0.9300000071525574, loss: 0.26591774821281433
Epoch: 400, accuracy: 0.8999999761581421, loss: 0.3307000696659088
Epoch: 500, accuracy: 0.9399999976158142, loss: 0.23977749049663544
Epoch: 600, accuracy: 0.9800000190734863, loss: 0.09397666901350021
Epoch: 700, accuracy: 0.9200000166893005, loss: 0.2931550145149231
Epoch: 800, accuracy: 0.9399999976158142, loss: 0.20180968940258026
Epoch: 900, accuracy: 0.949999988079071, loss: 0.18461622297763824
Epoch: 1000, accuracy: 0.9700000286102295, loss: 0.18968147039413452
Epoch: 1100, accuracy: 0.9599999785423279, loss: 0.14828498661518097
Epoch: 1200, accuracy: 0.949999988079071, loss: 0.1613173633813858
Epoch: 1300, accuracy: 0.9800000190734863, loss: 0.10008890926837921
Epoch: 1400, accuracy: 0.9900000095367432, loss: 0.07440848648548126
Epoch: 1500, accuracy: 0.9599999785423279, loss: 0.1167958676815033
Epoch: 1600, accuracy: 0.9100000262260437, loss: 0.1591644138097763
Epoch: 1700, accuracy: 0.9599999785423279, loss: 0.10022231936454773
Epoch: 1800, accuracy: 0.9700000286102295, loss: 0.1086776852607727
Epoch: 1900, accuracy: 0.9700000286102295, loss: 0.15659521520137787
Epoch: 2000, accuracy: 0.9599999785423279, loss: 0.09391114860773087
Epoch: 2100, accuracy: 0.9800000190734863, loss: 0.09786181151866913
Epoch: 2200, accuracy: 0.9700000286102295, loss: 0.11428779363632202
Epoch: 2300, accuracy: 0.9900000095367432, loss: 0.07231700420379639
Epoch: 2400, accuracy: 0.9700000286102295, loss: 0.09908157587051392
Epoch: 2500, accuracy: 0.9599999785423279, loss: 0.15657338500022888
Epoch: 2600, accuracy: 0.9900000095367432, loss: 0.07787769287824631
Epoch: 2700, accuracy: 0.9800000190734863, loss: 0.07373256981372833
Epoch: 2800, accuracy: 0.9700000286102295, loss: 0.062044695019721985
Epoch: 2900, accuracy: 0.9700000286102295, loss: 0.12512363493442535
Epoch: 3000, accuracy: 0.9900000095367432, loss: 0.11000598967075348
Epoch: 3100, accuracy: 0.9700000286102295, loss: 0.20609986782073975
Epoch: 3200, accuracy: 0.9800000190734863, loss: 0.09811186045408249
Epoch: 3300, accuracy: 0.9700000286102295, loss: 0.09816547483205795
Epoch: 3400, accuracy: 0.9700000286102295, loss: 0.10826745629310608
Epoch: 3500, accuracy: 0.9900000095367432, loss: 0.0645124614238739
Epoch: 3600, accuracy: 0.9700000286102295, loss: 0.1555529236793518
Epoch: 3700, accuracy: 0.9700000286102295, loss: 0.06963416188955307
Epoch: 3800, accuracy: 0.9900000095367432, loss: 0.08054723590612411
Epoch: 3900, accuracy: 0.9800000190734863, loss: 0.06120322644710541
Epoch: 4000, accuracy: 0.9900000095367432, loss: 0.06058483570814133
Epoch: 4100, accuracy: 0.9700000286102295, loss: 0.11490124464035034
Epoch: 4200, accuracy: 0.9700000286102295, loss: 0.10046141594648361
Epoch: 4300, accuracy: 0.9800000190734863, loss: 0.04671316221356392
Epoch: 4400, accuracy: 0.9900000095367432, loss: 0.052477456629276276
Epoch: 4500, accuracy: 0.9800000190734863, loss: 0.08245706558227539
Epoch: 4600, accuracy: 0.9900000095367432, loss: 0.041497569531202316
Epoch: 4700, accuracy: 0.9900000095367432, loss: 0.050769224762916565
Epoch: 4800, accuracy: 0.9900000095367432, loss: 0.039090484380722046
Epoch: 4900, accuracy: 0.9900000095367432, loss: 0.0564178042113781
testing accuracy: 0.9653000235557556
Questions to Ponder
- Why is the test accuracy lower than the (final) training accuracy ?
- Why is there only a nonlinearity in our hidden layer, and not in the output layer?
- How can we tune our hyperparameters? In practice, is it okay to continually search for the best performance on the test dataset?
- Why do we use only 100 examples in each iteration, as opposed to the entire dataset of 50,000 examples?
Exercises
- Using different activation functions. Consult the Tensorflow documentation on
tanhandsigmoid, and use that as the activation function instead ofrelu. Gauge the resulting changes in accuracy. - Varying the number of neurons - as mentioned, we have complete control over the number of neurons in our hidden layer. How does the testing accuracy change with a small number of neurons versus a large number of neurons? What about the generalization accuracy (with respect to the testing accuracy?)
- Using different loss functions - we have discussed the cross entropy loss. Another common loss function used in neural networks is the MSE loss. Consult the Tensorflow documentation and implement the
MSELoss()function. - Addition of another hidden layer - We can create a deeper neural network with additional hidden layers. Similar to how we created our original hidden layer, you will have to figure out the dimensions for the weights (and biases) by looking at the dimension of the previous layer, and deciding on the number of neurons you would like to use. Once you have decided this, you can simply insert another layer into the network with only a few lines of code:
- Use
weight_variable()andbias_variable()to create new variables for the additional layer (remember to specify the shape correctly). - Similar to computing the activations for the first layer,
h_1 = tf.nn.relu(...), compute the activations for your additional hidden layer. - Remember to change your output weight dimensions in order to reflect the number of neurons in the previous layer.
- Use
More
- Adding dropout
- Using momentum optimization or other optimizers
- Decaying learning rate
- L2-regularization
*Technical note: The way this loss function is presented is such that activations corresponding to a label of zero are not penalized at all. The full form of the cross-entropy loss is given by \(C(y, h(x)) = \sum_i y_i log(h(x_i)) + (1 - y_i)(log(1 - h(x_i))\). However, the previously presented function works just as well in environments with larger amounts of data samples and training for many epochs (passes through the dataset), which is typically the case for neural networks.